
John Cho, Tria Federal’s Chief Technology Officer, examines the impact of emerging technologies through his unique perspective. In this blog, he explores how machine learning can help to mitigate the risk of fraud, waste and abuse.
Artificial intelligence, including machine learning, helps us in our day-to-day lives in ways we may not even think about, from autocompleting our sentences to providing us with real-time traffic alerts. But did you know that machine learning can also help organizations save billions of dollars?
Follow along as I explain how machine learning can play a critical role in addressing the far-reaching problem of fraud, waste, and abuse (FWA) in processing different types of claims for payment.
FWA happens when someone squanders money, obtains something of value through willful misrepresentation, or misuses their position of authority. Every year, FWA costs healthcare, financial services, and government organizations billions of dollars.
Let me walk you through a simple approach that illustrates how we can use machine learning to detect fraudulent claims in real time, creating an opportunity to save significant time and money.
![]()
Step 1: Flag Improper Claims
First, we take an inventory of past claims and apply flags to those known to be fraudulent. These confirmed fraudulent claims, flagged with a 1 in the chart below, are required for the training process; they are the examples that will teach the algorithm what fraud looks like. The claims labeled 0 are normal. Once we have flagged and stored known fraudulent claims, we can analyze the claims for patterns. One way to do that is through a business intelligence platform which can help gather, visualize and understand the claims data.

Step 2: Train a Machine Learning Model
Next, we send selected data sets that contain fraudulent claims to be trained in a supervised machine learning model. One algorithm used for this type of model is the support vector machine (SVM), which can classify claims in binary form as either a 1 or 0. The training process uses examples of known fraudulent claims to encode what fraud looks like into the model – in other words, which attributes characterize a fraudulent claim.

Step 3: Deploy the Model
Once the model is trained, it is deployed to flag suspected fraudulent claims in real time. The SVM can ingest, score and label new claims. If the attributes of a new claim are statistically similar to past fraudulent claims, the new claim gets flagged with a 1, meaning it is likely fraudulent. Otherwise, it gets a 0 and processing of the claim continues.
We then send those predictions back into the business intelligence tool.
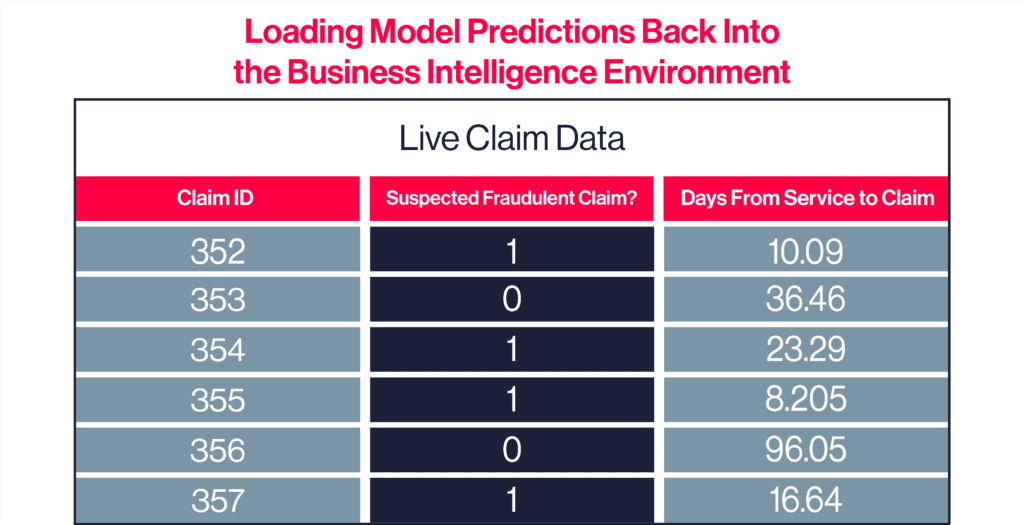
Step 4: Detect and Act
Then comes the final and arguably most critical step: dealing with suspected fraudulent claims.
The model reports a confidence score along with the flagged claim. If we are dealing with hundreds of potentially fraudulent claims each day, we can automatically reject claims flagged with high confidence, while requiring human review of those flagged with lower confidence. This generates tremendous time savings and reduces chances of error that come from a reviewer having to manually review hundreds or even thousands of claims.
Fraudulent activity is constantly evolving both in approach and sophistication. Hence, we need to refine and adapt the model to anticipate these changes. Continuing to train the model with every relevant type of fraud creates a virtuous cycle: the more data and greater variety of data we train our models on, the better they will perform.
As you can see, machine learning can help tackle FWA in meaningful ways: saving billions of dollars; saving time by reducing the amount of human review needed; and critically for all institutions—but especially governments–strengthening confidence and public trust by minimizing the impact of fraud, waste, and abuse. If you missed my first post on Demystifying AI, check it out here to learn how music streaming services use AI to understand your music preferences.
John Cho is Tria’s Chief Technology Officer, and the head of Tria Labs.